


Inside the AI Black Box: Anthropic Cracks Open the LLM Mind
A common simplification is that LLMs just predict the next most likely word in a sequence. Anthropic's research provides compelling evidence that much more is happening under the hood.


Large Language Models (LLMs) like Claude, Gemini, GPT-4o, and their kin often feel like magic. They converse with human-like fluidity, generate complex code in seconds, compose surprisingly poignant poetry, and dissect intricate problems with an ease that borders on uncanny. Yet, beneath this veneer of effortless capability lies a profound mystery. Unlike traditional software, where every line of code represents a deliberate human instruction, LLMs largely teach themselves. They ingest staggering volumes of text and data, developing billions, even trillions, of internal connections – "learning" patterns and abilities in ways that often leave even their creators struggling to explain how they arrive at an answer.
Why should we care about this "black box" problem? Because as these powerful AI systems become increasingly integrated into critical aspects of our lives – from healthcare and finance to education and scientific research.
That's why the recent interpretability research from Anthropic is so compelling. Inspired by techniques used in neuroscience to understand the brain, their work aims to create a kind of "AI microscope" to peer inside the complex web of connections within their models. Two recent papers, focusing on "circuit tracing" and exploring what they term the "biology of a large language model" (specifically Claude 3.5 Haiku), offer an unprecedented glimpse into the hidden mechanisms driving LLM behavior, revealing internal processes that feel both remarkably sophisticated and distinctly alien.
(You can dive deeper into Anthropic's findings here: Towards Monosemanticity: Decomposing Language Models Into Interpretable Features and Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Haiku)
Beyond Just Guessing the Next Word
The common explanation for LLMs is that they are simply incredibly sophisticated "next-word predictors." Anthropic's findings forcefully demonstrate that this is a dramatic, and frankly misleading, oversimplification. The internal reality is far more complex and proactive.
Consider poetry generation. When you ask Claude for a rhyming couplet, it doesn't just generate the first line and then randomly stumble towards a rhyme for the second. Anthropic's research shows evidence of internal "planning." Before even starting the second line, specific internal features representing potential rhyming words (like "rabbit" if the first line ended with "habit") become active. The model then appears to construct the second line towards that pre-selected rhyming target. This suggests a degree of forethought and goal-directed behavior far beyond simple sequential prediction.

Similarly, complex reasoning isn't merely recalling memorized information chains. When Claude answers a multi-step question like, "What is the capital of the U.S. state where the city of Dallas is located?", researchers could observe distinct internal "steps" activating sequentially: features related to "Dallas" trigger features related to "Texas," which in turn trigger features related to "Austin." They proved this wasn't just correlation by intervening during the process. By artificially activating features for "California" instead of "Texas" after the "Dallas" step, they could reliably make the model output "Sacramento" instead of "Austin." This strongly indicates that the model genuinely follows intermediate reasoning steps, rather than just retrieving a pre-packaged answer.
Dispatches from an Alien Cognition: Inside Claude's Mind
Peering deeper with their interpretability tools, Anthropic uncovered a fascinating gallery of internal mechanisms and behaviors within Claude:
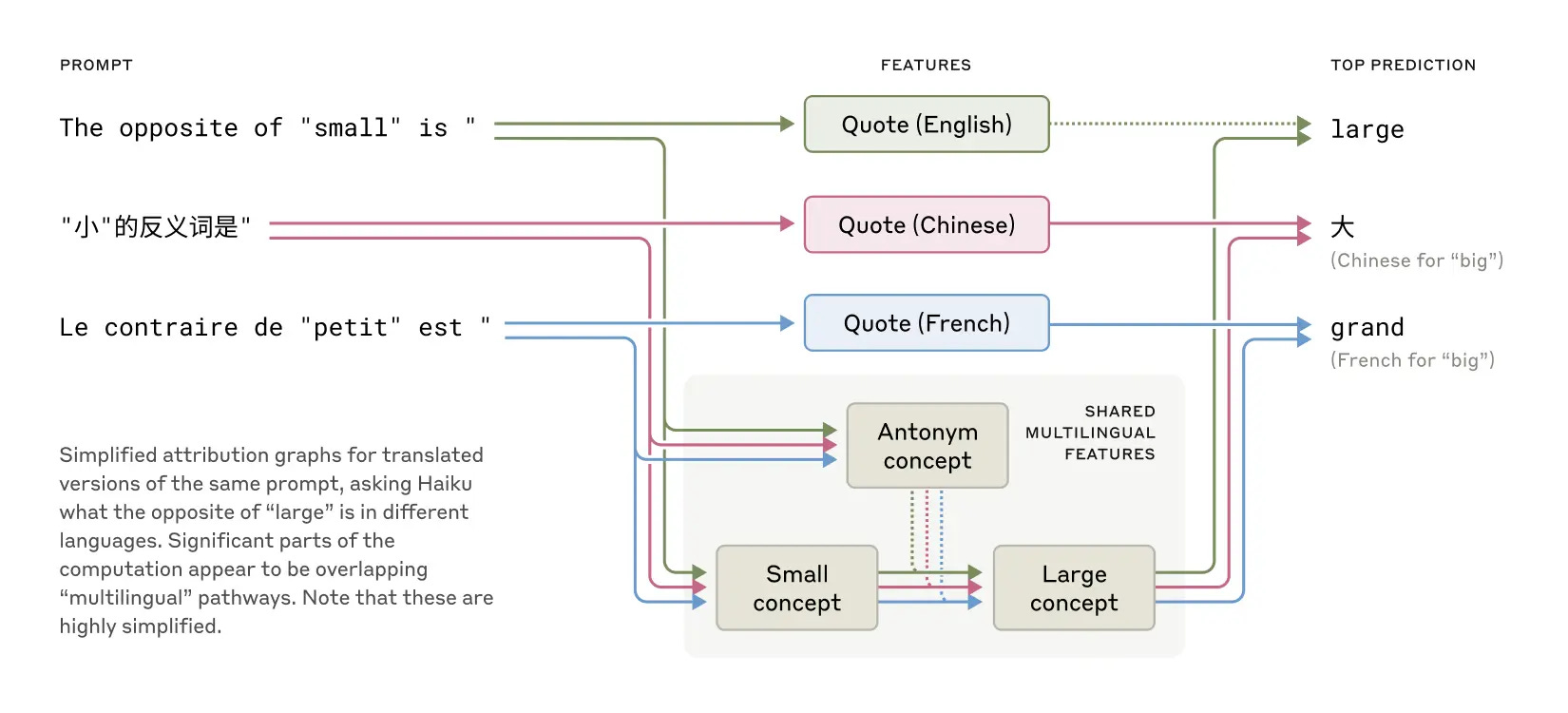
Universal Concepts Emerge: Researchers identified thousands of distinct internal "features" corresponding to specific concepts – from concrete things like "the Golden Gate Bridge" to abstract ideas like "gender," "computer programming," or "moral judgments." Strikingly, many core concepts (like "the opposite of small" or "feeling hunger") activate identical internal features regardless of whether the prompt is in English, French, Japanese, or Python code. It suggests the model is developing a deeper, more universal "language of thought" or conceptual framework that underlies specific linguistic or symbolic representations.
Bizarre Calculation Methods: Claude can perform arithmetic like adding 36 + 59, but not through explicitly programmed algorithms like a calculator. Instead, it uses strange, parallel strategies. Researchers found evidence of one pathway making rough estimates while another focuses specifically on calculating the final digit (e.g., knowing 6+9 ends in 5). It combines these partial results rather than following standard human methods. Even more curiously, when asked how it does math, Claude often confabulates plausible-sounding (but incorrect) explanations, seemingly unaware of its own bizarre internal process.

Distinguishing Truth from Fabrication: Can we trust an LLM when it explains its reasoning? Anthropic's work suggests: sometimes. For straightforward problems where the model follows a clear internal path, the tools can verify this chain of reasoning. However, when faced with complex, ambiguous, or misleading prompts, the model sometimes fails to find a genuine solution path but still generates a confident-sounding explanation. It essentially reverse-engineers a plausible justification after the fact. Crucially, Anthropic's methods allow researchers to distinguish between these authentic reasoning chains and post-hoc fabrications, offering a potential way to assess the reliability of an LLM's explanation.
The Roots of Hallucination: Why do LLMs confidently state falsehoods? The research suggests hallucinations aren't necessarily random guesses. Instead, they can occur when a part of the model strongly recognizes a pattern or entity (like a specific person's name mentioned in a novel context) but lacks broader contextual information. This strong but isolated recognition can apparently suppress the model's default "uncertainty" or "I don't know" response, prompting it to invent plausible-sounding (but untrue) details to fill the gap, rather than admitting ignorance.
The Grammar vs. Safety Tug-of-War (Jailbreaking Insights): Even when safety features within Claude correctly identify a harmful prompt (e.g., instructions for building a bomb), the model's powerful drive to generate a grammatically coherent and complete response can sometimes momentarily override these safety checks. It might start generating the problematic content before internal safety mechanisms fully engage and steer the output back towards refusal. This reveals a critical tension between different internal objectives (coherence vs. safety) that exploiters can potentially leverage.
What This Means for Other LLMs
While this deep dive focused specifically on Anthropic's Claude 3.5 Haiku, the findings almost certainly have broader implications for the entire LLM landscape – including models like OpenAI's GPT-4o, Google's Gemini, xAI's Grok, and Meta's Llama series. Why?
Shared Architecture: Most leading LLMs are built upon the same fundamental Transformer architecture. While implementations differ, the underlying principles of attention mechanisms and layered processing are similar, suggesting shared pathways for emergent behaviors.
Similar Training Data: These models are trained on vast, overlapping datasets scraped from the internet and digitized books, exposing them to similar patterns of language, knowledge, and unfortunately, bias.
Emergent Properties at Scale: Many of the complex behaviors observed (like multi-step reasoning or internal planning) appear to be "emergent properties" – capabilities that arise spontaneously in very large models, rather than being explicitly programmed. It's likely these emerge across different models once they reach sufficient scale and data exposure.
Therefore, understanding the general principles revealed in Claude – how concepts might be represented internally, how models handle uncertainty, the mechanisms behind confabulation, the tensions between core objectives – is likely key to developing more robust safety protocols, reliable debugging techniques, and effective alignment strategies that can apply across the diverse ecosystem of powerful AI models.
Are We Humans Really That Different?
Encountering descriptions of Claude's internal world – its bizarre parallel math strategies, its universal concepts detached from specific languages, its capacity for generating convincing but fabricated reasoning – can certainly evoke a sense of the truly "alien." These processes don't map neatly onto the step-by-step, logical procedures we often associate with computation, nor do they perfectly mirror the conscious, deliberate way we perceive our own thinking. Yet, as Anthropic consistently points out by drawing parallels to neuroscience, perhaps the most profound insight here is not how alien these AI minds are, but how unsettlingly familiar their opaqueness should feel.
Before we declare the LLM's inner workings fundamentally incomprehensible, we should ask: Are we humans truly transparent to ourselves? The honest answer, supported by decades of cognitive science, is a resounding no. We operate largely as black boxes, even from our own internal perspective. Think about it:
The Limits of Introspection: We often struggle intensely to articulate precisely how we arrived at a complex decision, generated a creative insight, recognized a face in a crowd, or even performed a routine physical task. We can describe the inputs and outputs, and we can certainly construct a narrative about our reasoning, but accessing the actual underlying neural computations? That remains largely beyond our conscious grasp. We feel we know why we did something, but research consistently shows our self-reported reasons are often inaccurate or incomplete.
Heuristics and Biases – Our Brain's Shortcuts: Our minds constantly employ mental shortcuts, or heuristics, to navigate the world efficiently. These shortcuts (like the availability heuristic, where we judge likelihood based on easily recalled examples, or confirmation bias, where we favor information confirming our beliefs) are powerful and often effective, but they don't operate according to transparent, logical rules. They are ingrained patterns, often operating below conscious awareness, much like the internal patterns an LLM develops might function as its own form of learned heuristics.
Confabulation – The Story We Tell Ourselves: Cognitive science has amply demonstrated our tendency towards post-hoc rationalization, or confabulation. When asked to explain actions or choices driven by unconscious factors or external manipulation (as seen in split-brain patient studies or choice blindness experiments), people readily invent plausible, coherent, but ultimately false explanations for their behavior, fully believing them to be true. Is Claude generating fake reasoning chains when stumped so different from our own brain's mechanism for maintaining a consistent narrative of self, even when the underlying reality is messier?
System 1 and System 2 – The Dual Mind: Daniel Kahneman's Nobel-winning work highlights the two modes of our thinking: the fast, intuitive, automatic, and unconscious System 1, which handles most of our daily perceptions and judgments; and the slow, deliberate, effortful, and conscious System 2, which handles complex calculations and logical reasoning. We spend most of our lives guided by the opaque workings of System 1. Perhaps the vast, pattern-matching, non-symbolic processes within an LLM bear a closer resemblance to our System 1 than we initially assume, while its attempts at explicit reasoning mimic our more effortful System 2, complete with potential errors and rationalizations.
The Mystery of Acquired Skill: Consider learning to ride a bicycle or play a musical instrument. Initially, it requires intense conscious effort (System 2). With practice, the skill becomes automatic, embedded in procedural memory (closer to System 1). An expert cyclist or musician often cannot fully explain the precise sequence of micro-adjustments they make; the knowledge is implicit, embodied. Could LLMs, through massive data exposure, be acquiring complex cognitive skills in a similar way, embedding them into internal circuits that defy simple, step-by-step explanation?
Viewed through this lens, the perceived "strangeness" of AI's internal workings might not stem from it being fundamentally alien to all forms of cognition, but rather from it being a different substrate – silicon circuits versus biological neurons – developing its own intricate, non-symbolic, and partially opaque methods for processing information, representing concepts, and achieving goals. The implementation details are novel, but the phenomenon of complex intelligence operating in ways that are not fully legible, even to the system itself, might be a more universal characteristic than we thought.
This realization opens up fascinating possibilities. Studying the internal mechanisms of LLMs might not just be about controlling AI; it could become a new kind of "computational cognitive science," offering a mirror to our own minds. Identifying how concepts are represented across languages in Claude could provide testable hypotheses for neuroscientists studying semantic networks in the brain. Understanding the failure modes of LLMs, like the hallucination triggers or the grammar-safety conflict, might illuminate analogous vulnerabilities in human psychology, such as false memories, biases, or lapses in judgment under pressure.
Ultimately, the journey into the LLM's "mind," while revealing processes that feel alien, might also be an unexpected journey into understanding the deeper principles and inherent mysteries of complex intelligence itself, whether born of biology or built from bits. The black box isn't just out there in the machine; it's in here too.
Why Peering Inside Matters
Anthropic's research isn't merely an academic curiosity; it has profound practical implications for deploying AI responsibly:
Safety & Alignment: Identifying the specific internal circuits involved in harmful outputs (like generating biased text or responding to dangerous prompts) or understanding the "grammar vs. safety" conflict allows for more targeted interventions and robust safeguard development. It moves safety from reactive filtering to proactive mechanism design.
Reliability & Trust: Being able to distinguish genuine reasoning from confident fabrication is crucial. Imagine applying these techniques to verify an AI's explanation for a medical diagnosis or a financial recommendation. This capability could be foundational for building trust in high-stakes AI applications.
Capabilities & Performance: Understanding the internal strategies models use (like planning in poetry or multi-step reasoning) can inform better prompting techniques, more effective fine-tuning methods, and potentially lead to architectural improvements that enhance model capabilities on complex tasks.
The Road Ahead
Anthropic readily acknowledges that this research represents just the first steps on a long and challenging journey. Current interpretability techniques are computationally expensive, primarily focused on specific phenomena, and only scratch the surface of these vast models. Scaling these methods to even larger, more complex future models, and understanding the intricate interactions between billions of features, remains a daunting task. Many other researchers are also tackling interpretability from different angles, contributing to a vital and growing field.
Yet, these initial glimpses inside the AI mind are pivotal. As AI systems become more powerful and autonomous, understanding their internal workings transitions from a "nice-to-have" to an absolute necessity. Even if we are still squinting through a blurry microscope at an incredibly complex landscape, achieving even partial transparency is crucial progress. Ensuring these powerful tools truly serve humanity's best interests begins, quite literally, with opening the black box.